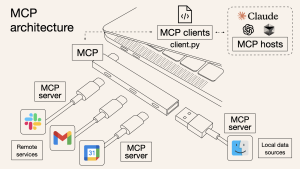
RAGの精度向上する方法 Retrieval-Augmented Generation(RAG)は、情報検索とテキスト生成モデルを組み合わせた強力な手法であり、チャットボットやAIシステムがより正確で文脈に沿った回答を提供できるようにします。しかし、高い精度を達成するためには、情報検索(retrieval)とテキスト生成(generation)の両段階で最適化技術を適用する必要があります。ここでは、RAGのパフォーマンスを向上させるための詳細な方法を紹介します。 目次 情報検索フェーズの改善 埋め込みモデル(Embedding)の選択と最適化埋め込みモデル(embedding model)は、関連情報を検索する際の基盤となります。最適化のための方法として以下のものがあります。特化した埋め込みモデルの使用: OpenAIのtext-embedding-ada-002のような汎用モデルを使う代わりに、自社のデータセットに特化した埋め込みモデルをファインチューニングすると精度が向上します。複数の埋め込みモデルを組み合わせる: さまざまなembedding modelsを活用し、検索のカバレッジを広げることで、より適切な情報を取得できます。ベクトルの正規化: L2正規化(L2-normalization)などの手法を活用し、ベクトルの距離計算がより意味のあるものになるように調整します。 インデックス作成と検索クエリの最適化FAISSまたはAnnoyの使用: 高速なインデックス作成と検索を実現するために、FAISSやAnnoyのようなライブラリを利用します。クエリ最適化技術の導入: クエリ拡張(query expansion)や再ランキング(re-ranking)を組み合わせることで、適切な情報の選択精度を向上させます。メタデータフィルタリングの活用: データにタイムスタンプやカテゴリなどのメタデータがある場合、それを活用して検索範囲を狭めることで、検索結果の精度を向上させます。 リランキング(Reranking)の適用高精度なリランキングモデルの使用: Cohere RerankやCross-Encoderなどの高度なリランキングモデルを活用し、取得した情報を最も適した順に並び替えます。コンテキストに基づいたリランキング: 単なるベクトル類似度に依存するのではなく、クエリの文脈を考慮したリランキングを行うことで、より的確な情報を提供できます。 テキスト生成フェーズの改善 入出力の制御プロンプトエンジニアリングの強化: 適切なプロンプト設計を行うことで、モデルがクエリを正しく理解し、精度の高い回答を生成できるようにします。出力の長さを制限: 生成される回答が冗長にならないように、適切な長さを設定し、簡潔で要点を押さえた内容にします。後処理(Post-processing)の活用: 生成されたテキストに対してヒューリスティック処理や別のモデルを適用し、誤りを減らします。 ファクトチェックの統合ファクトチェックモデルの使用: LlamaIndexなどのファクトチェック機能を備えたモデルを組み合わせることで、誤った情報の生成を防ぎます。情報源の明示: 生成された回答に出典情報を付与することで、ユーザーが情報を検証しやすくなります。盗用チェックモデルの適用: モデルが不適切なコピーや誤情報を生成しないよう、盗用チェックを実施します。 温度(Temperature)とサンプリング手法の調整温度(Temperature)の低減: モデルの一貫性を向上させるために、temperatureの値を低く設定します。ビームサーチやNucleus Samplingの使用: greedy decodingの代わりに、ビームサーチやNucleus Samplingを活用し、より適切な回答を生成します。適応型温度調整(Temperature Adaptive): クエリの複雑さに応じて温度を動的に変更し、柔軟なテキスト生成を実現します。 継続的な監視と改善 ユーザーフィードバックの収集: ユーザーのフィードバックを蓄積し、システムの問題点を特定します。フィードバックに基づいたモデルのファインチューニング: 収集したデータを活用し、検索・生成モデルの両方を改善します。A/Bテストの実施: 異なるRAGのバージョンをテストし、最適な設定を見つけます。自動モニタリングと評価: 回答の品質をリアルタイムで評価し、エラーを検出して改善につなげます。 RAGを支える最新技術 高度なベクトルデータベースの活用: Pinecone、Weaviate、Milvusなどのベクトルデータベースを使用し、検索速度と精度を向上させます。ナレッジグラフ(Knowledge Graphs)の統合: 知識グラフを組み込むことで、RAGの意味理解能力を強化し、より正確な情報を提供します。ハイブリッド検索の適用: ベクトル検索(semantic search)と従来のBM25検索を組み合わせることで、検索の精度を向上させます。 まとめ RAGの精度を向上させるには、検索モデルの最適化、生成精度の向上、ファクトチェックの統合など、多岐にわたる対策が必要です。適切な技術と継続的な改善を施すことで、より正確で信頼性の高いAIアシスタントを構築できるでしょう。システムのモニタリングと最適化を継続しながら、ユーザーにとって価値のあるRAGを提供していきましょう。 You Might Also Like Model Context Protocol(MCP)とは 18/04/2025 n8nでGoogle Drive + Pinecone + GPT-4oを活用したRAGシステムの構築 23/02/2025 RAG (検索拡張生成) とは何ですか? 09/11/2024